-
A. Introduction
- B. Configuration
- C. Normes de saisie
- D. Importation
- E. Exportation
- F. Transformation XSLT
-
G. Réservé
- H. Administration avancée
- I. Programmer BaseDeFiches
- Z. Annexes
Introduction à XSLT
Lorsque l’on demande l’affichage d’une fiche, son contenu est formaté en HTML, le langage bien connu de la Toile. Or les données des fiches sont stockées en XML ; pour afficher une fiche, le logiciel doit donc effectuer la transformation des données XML en code HTML. Cette transformation est assurée à l’aide du langage XSLT.
Le langage XSLT est un langage en XML conçu spécifiquement pour assurer la transformation de n’importe quel format XML vers n’importe quel autre format XML. Son usage le plus courant est la transformation d’un format XML en HTML et il permet également via le langage XSL-FO de générer un fichier PDF.
Le processus de transformation est décrit dans le schéma ci-dessous :
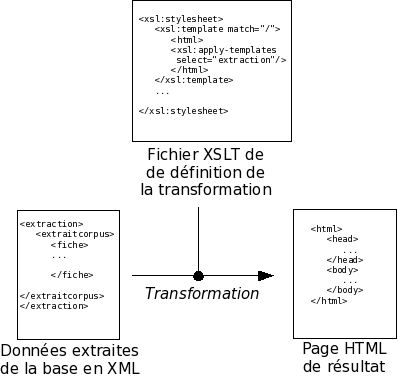
Schéma d’une transformation XSLT
On peut voir ainsi un fichiers XSLT comme un modèle d’affichage des données.
Le logiciel BaseDeFiches propose ainsi un modèle d’affichage par défaut des fiches mais aussi des compilation de fiches et des statistiques par thésaurus en générant automatiquement des fichiers XSLT reprenant les informations de l’interface (ordre des champs, commentaires insérés, etc.). On peut donc utiliser le logiciel BaseDeFiches sans se soucier de XSLT.
Le passage par XSLT est cependant indispensable dans les deux cas suivants :
-
1) Lorsque l’on veut personnaliser les modèles d’affichage de façon plus subtile que ne le permet l’insertion de commentaires (par exemple, insérer un entête avec un logo, privilégier une mise en forme tabulaire, regrouper plusieurs champs, etc.).
-
2) Lorsque l’on veut générer un site web à partir des données de la base : c’est le processus qui est désigné sous le terme de balayage.
L’utilisation de XSLT demande de maitriser trois éléments :
-
le langage XSLT lui-même
-
le langage HTML et son corolaire, le CSS
-
le format XML d’extraction
L’apprentissage de XSLT n’entre pas dans le cadre du présent document ; on conseillera l’ouvrage Comprendre XSLT de Bernd Amann et Philippe Rigaux aux éditions O’Reilly. BaseDeFiches fournit un grand nombre de règles XSLT prêtes à l’emploi pour toutes les données susceptibles d’être extraites de la base. En outre, le logiciel propose une approche simplifiée de XSLT qui permet d’adapter relativement facilement un modèle d’affichage sans avoir à se plonger dans XSLT.
L’apprentissage de HTML ne fait pas non plus bien sûr l’objet du présent document. Le seul point qui doit rester à l’esprit, c’est qu’il s’agit en fait de XHTML plutôt que de HTML : il faut appliquer la rigueur des normes XML et oublier le laxisme du HTML.
Le format XML d’extraction est abordé dans un chapitre particulier. Il est évidemment nécessaire de comprendre la façon dont il est construit afin de pouvoir appliquer du XSLT dessus. Dans un premier temps, on peut se contenter du format par défaut qui suffit pour les modèles d’affichage, le paramétrage du format d’extraction n’est utile que pour les balayages.
La façon la plus simple pour apprendre XSLT est de partir de l’existant et de procéder par petites touches en modifiant progressivement un fichier existant.
Il est possible d’avoir un aperçu du fichier XSLT par défaut ainsi que du format XML d’extraction des données en procédant la façon :
1) Avec une fiche quelconque, cliquer avec le bouton droit sur le lien « afficher » et copier l’adresse du lien ; pour la fiche de suivi n°1 de notre base d’exemple, cela donnerait :
http://www.basedefiches.net:8080/exemple/fiches/suivi-1.html
2)En remplaçant l’extension .html par .xml, s’affiche le navigateur le fichier XML tel qu’il est fourni au processeur XSLT avant transformation. Exemple :
http://www.basedefiches.net:8080/exemple/fiches/suivi-1.xml
3) En remplaçant l’extension .html par .xsl, on est redirigé vers l’URL affichant le fichier XSLT utilisé pour la transformation. Exemple :
http://www.basedefiches.net:8080/exemple/fiches/suivi-1.xsl
est redirigé vers
http://www.basedefiches.net:8080/exemple/xslt/_default_corpus_suivi.xsl
4) Enfin, en remplaçant l’extension .xsl par .txt, on voit s’afficher le code du XSLT simplifié. Exemple :
http://www.basedefiches.net:8080/exemple/xslt/_default_corpus_suivi.txt
Ces procédures permettent de récupérer des fichiers fonctionnels qui peuvent servir de base de départ à une adaptation.